AI Pilot Integration Cliffs: Why Monday Breaks the Demo
Many AI pilots fail at integration, not model quality. Production success requires workflow bridges, ownership, and source-of-truth discipline.
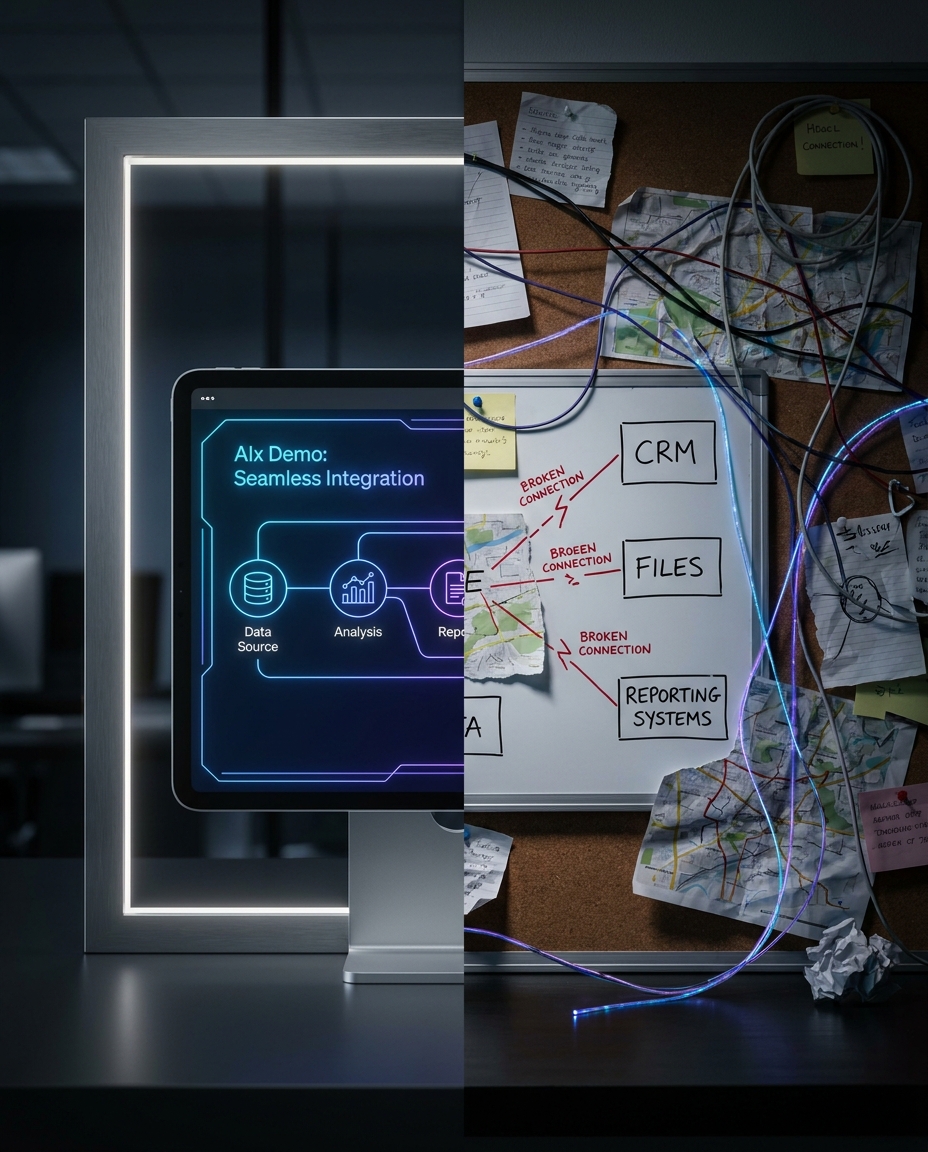
Early AI demos often look convincing. Responses are fast, the use case appears clear, and teams begin discussing scale quickly.
Then production reality arrives. Systems disagree, handoffs fail quietly, and a “temporary manual step” becomes permanent.
This is the integration cliff: a pilot that performs in controlled conditions but weakens when it touches real workflows, permissions, and operational data rules.
Why pilots break after the demo
Most teams do not fail because the model is weak. They fail because the workflow was never wired for production.
Common failure points:
- CRM and source documents conflict with no resolution rule
- integrations fail silently when APIs change
- retries stack without clear alert ownership
- multiple “final” files exist across channels
- no agreed system of record
None of these are solved by a better prompt.
The cost of skipping integration design
When integration logic is unclear, teams absorb the cost through coordination overhead:
- more manual review
- more exception handling by ad hoc messages
- slower decisions under deadline pressure
- weaker trust in the transformation program
The pilot may still be labeled “successful,” but operations tell a different story.
Integration before models: a practical sequence
Before adding the next AI layer, teams should map one workflow end-to-end:
- Who owns each handoff?
- Which system wins when records disagree?
- Where does approved data land?
- What does “done” mean for each stakeholder?
- Who is accountable when production breaks?
If those answers are incomplete, new AI capability will likely accelerate confusion instead of reducing friction.
Build the bridges first
A durable implementation starts with bridge quality:
- explicit source-of-truth rules
- monitored connector behavior
- exception routing with owners
- change management for vendor/API updates
- operational runbooks for incident response
Only then should teams optimize model quality or expand coverage.
One-lane rule for real progress
Choose one live workflow and walk it slowly before scaling:
- intake
- transformation
- approval
- handoff
- downstream update
Fix bridge failures in that lane. Validate it under messy inputs and real exceptions. Then expand.
This is slower than demo velocity in week one, but faster than six months of rework.
Integration health checklist
Before declaring a pilot “ready,” run this checklist:
- Data parity: source systems reconcile on key fields with explicit conflict rules.
- Connector resilience: failures trigger alerts and retries are monitored.
- Ownership clarity: every handoff has a named accountable role.
- Exception routing: low-confidence cases have defined queue and SLA.
- Replayability: teams can reconstruct what happened for one transaction in minutes.
If two or more checks fail, pause expansion and fix the lane first. This discipline protects credibility and ensures model improvements land inside a reliable operating path.
Closing
Most pilot disappointment is integration debt in disguise.
If your last initiative passed in narrow test conditions and failed in rollout, start at the bridges, not the model. Production reliability comes from honest pipes, clear ownership, and defined system rules.
For leadership teams, this reframing is useful: integration quality is not technical overhead, it is revenue protection. Every failed handoff creates avoidable delay and trust erosion that compounds across departments.
Models matter. Integration discipline determines whether they survive Monday.